
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 엔터티
- 정규화
- CROSS JOIN
- outer join
- 백준
- BFS
- bottleneck
- Inductive Bias
- 인접리스트
- pytorch
- 1x1 Convolution
- dp
- mobilenet
- 데이터모델링
- 인접행렬
- resnet
- Depthwise Separable Convolution
- SQLD
- SQL
- 연산량 감소
- numpy
- dfs
- get_dummies()
- SQLD 후기
- Two Pointer
- depthwise convolution
- feature map
- skip connection
- 그래프
- 식별자
- Today
- Total
SJ_Koding
결정계수 (R2 Score)의 설명 및 Python 구현 본문
*주의!! SSE는 SSR로도 표기될 수 있고 SSR은 SSE로 표기되기도 함. 수식을 통해 어떤 SSE(Explained? Error?), SSR(Residual?, Regression?)인지 파악이 먼저 필요하다.
(본 포스팅은 김성범교수님의 유튜브 영상을 참고하여 정리되었습니다.)
R2 Score
결정 계수는 R2 Score라고 불리고 선형 회귀 분석시 사용되는 회귀 모델의 적합도를 나타내는 지표 중 하나이다. 주어진 데이터에 대해 모델이 얼마나 잘 적합되었는지를 설명한다. R2 score는 0과 1사이의 값으로 나타나고, 높을수록 모델이 데이터를 잘 설명한다는 것을 의미한다. R2 Score의 수치는 예측 모델이 실제 모델과 얼마나 강한 상관관계를 가지느냐로 설명되기도 한다.
R2 Score를 구하기 위해 SST, SSE, SSR 의 용어를 이해해야한다.

SST ( Total sum of squares ) : 총 변동, 실제 값과 평균과의 오차의 제곱을 모두 합한 값.

SSE ( Explained sum of squares ) : 설명된 변동, 예측값과 평균값의 오차의 제곱을 모두 합한 값.
(* 책에 따라 SSR(Regression Sum of squares로 표기하는 경우도 있음 이때 Residual의 R과 혼동 XX)
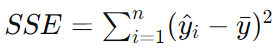
SSR ( Residual sum of squares ) : 설명되지 않은 변동, 실제값과 예측값의 오차의 제곱을 모두 합한 값
(* 책에 따라 SSE(Error Sum of squares로 표기하는 경우도 있음 이때 Explained의 E와 혼동 XX)


그림으로 뜯어보자.

SSE/SST = 1
여기서 SSE/SST = 1이라는 것, 즉 SSR이 0이라는 것은 오차 없이 점들이 모두 회귀 모델 선상에 위치한다는 것이다.
(에러가 하나도 없다.) 즉, 모든 X가 모든 Y를 완벽하게 설명하고 있다라고 해석할 수 있다.
SSE/SST = 0
반대로, SSE가 0이라면 X가 Y를 전혀 설명하고 있지 못한다는 뜻이다. SST가 SSR과 동일하다는 이야기인데, 즉, Y의 평균으로 설명되는것 보다 X에 의해 설명되는 것이 '없다'라는 뜻이다.
SSE/SST 가 R2-score(결정계수)
SSE/SST 혹은 1 - (SSR/SST)가 바로 결정계수이다. X가 Y를 얼마나 잘 설명하냐를 의미한다.
요약하면 r2스코어가 1이면 가지고있는 X변수로 Y를 100% 설명할 수 있다는 뜻. 즉, 모든 관측치가 회귀직선 위에 있다는 것이며
r2스코어가 0이면 X변수는 Y설명에 전혀 도움이 되지 않는다는 의미이다.
따라서 당연히 r2-score가 1에 가까울 수록 좋은 설명력을 가지게 된다. == validation_r2_score가 1에 가까우면 짱짱 좋은 회귀모델일 가능성 큼
R2-score의 다양한 해석
1. 사용하고 있는 X변수가 Y변수의 분산을 얼마나 줄였는지의 정도
2. 단순히 Y의 평균값을 사용했을 때 대비 X 정보를 사용함으로써 얻는 성능향상 정도
3. 사용하고 있는 X변수의 품질
R2 Score 파이썬 구현
주어진 수식대로 구현하면 된다. 간단하다.
def calculate_r2(y_true, y_pred):
"""
실제 값과 예측 값으로 R2 점수, SST, SSE, SSR을 계산합니다.
Args:
y_true: 실제 값 (30개)
y_pred: 예측 값 (30개)
Returns r2: 결정계수
sst: 총제곱합
ssr: 회귀제곱합
sse: 설명제곱합
"""
# 1. 평균값 계산
y_mean = sum(y_true) / len(y_true)
# . SST, SSE, SSR 계산
sst = sum([(y - y_mean)**2 for y in y_true])
ssr = sum([(y - pred)**2 for y, pred in zip(y_true, y_pred)])
sse = sst - ssr
# 3. R2 계산
r2 = 1 - (ssr / sst)
return r2, sst, sse, ssr
# 예시 데이터
np.random.seed(0) # 결과의 일관성을 위해 seed를 설정합니다.
y_true = np.random.normal(loc=0.0, scale=1.0, size=30)
y_pred = y_true + np.random.normal(loc=0.0, scale=0.2, size=30)
# R2, SST, SSE, SSR 계산
r2, sst, sse, ssr = calculate_r2(y_true, y_pred)
# 결과 출력
print(f"R2 점수: {r2}")
print(f"SST: {sst}")
print(f"SSE: {sse}")
print(f"SSR: {ssr}")출력결과:
R2 점수: 0.9695208338570169
SST: 35.11095611622026
SSE: 34.04080345131499
SSR: 1.0701526649052637R2 score sklearn라이브러리 사용해서 구하기
from sklearn.metrics import r2_score
r2 = r2_score(y_true, y_pred)
print(f"R2 점수: {r2}")출력 결과:
R2 점수: 0.9695208338570169'Data analysis > etc' 카테고리의 다른 글
| OpenCV-Python 명령어 정리 (1 ~ 15) (0) | 2022.03.20 |
|---|---|
| Precision(정밀도)와 Recall(재현율)의 의미와 예시 그리고 F1-score에 대하여. (2) | 2022.03.12 |

