
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- dp
- Depthwise Separable Convolution
- 백준
- 식별자
- SQL
- 연산량 감소
- bottleneck
- numpy
- 인접리스트
- 정규화
- depthwise convolution
- 1x1 Convolution
- 인접행렬
- 엔터티
- outer join
- CROSS JOIN
- Inductive Bias
- dfs
- resnet
- 그래프
- BFS
- 데이터모델링
- mobilenet
- feature map
- SQLD 후기
- Two Pointer
- get_dummies()
- pytorch
- SQLD
- skip connection
- Today
- Total
SJ_Koding
pandas, Ont-Hot인코딩 하는 법 (pd.get_dummies()) 본문
pandas 패키지는 자동으로 범주형 데이터에 대해 One-Hot인코딩을 진행하는 메소드가 존재합니다.
pd.get_dummies()
결과를 미리 보여드립니다.
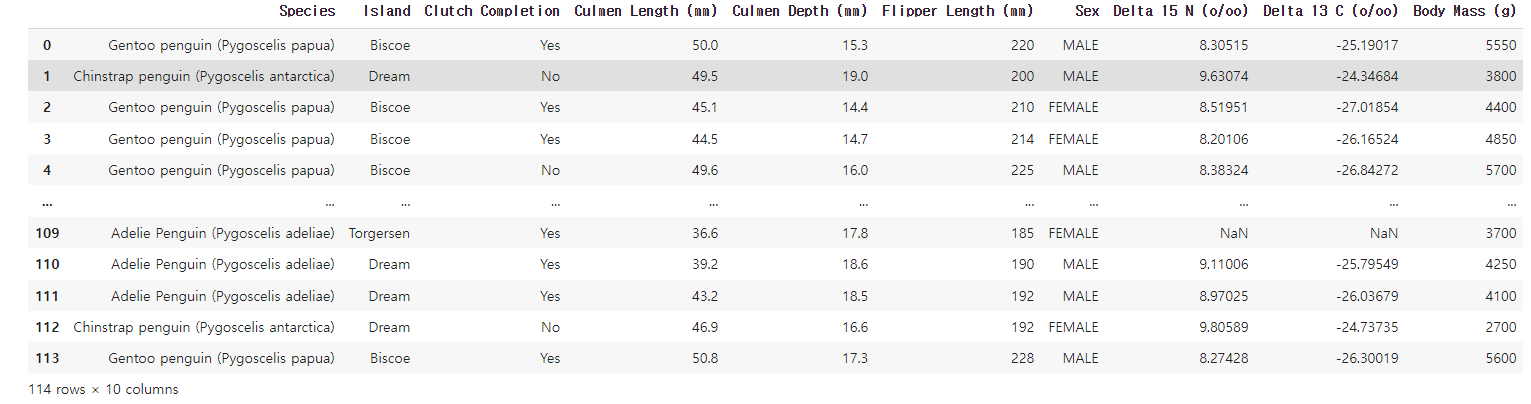
df_train = pd.get_dummies(df_train)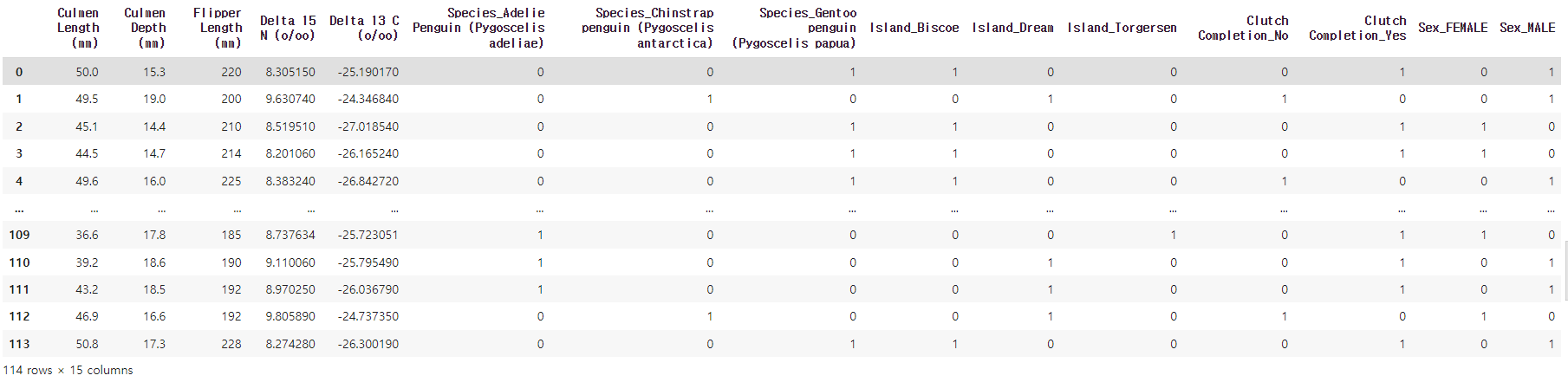
컬럼의 수가 10개에서 15개로 증가하였고, string형에 대한 데이터들에 대해 모두 One-Hot인코딩이 진행된 모습입니다.
사용 방법은 위에 제시되었지만 자세히 알려드립니다.
먼저 예시로 제시된 데이터는 데이콘에서 진행되는 '펭귄 몸무게 예측 경진대회'에서 제공된 데이터 셋입니다.
https://dacon.io/competitions/official/235862/data
펭귄 몸무게 예측 경진대회 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
(데이터를 불러오는 과정은 생략합니다.) 데이터의 변수명를 df_train이라고 하겠습니다.

먼저 df_train.info()를 통해 특징들을 조회해보면 non-null의 개수가 다른 컬럼들을 볼 수 있으며 object형의 컬럼이 아주 많이 보입니다. 학습을 위해서는 모두 처리해주어야합니다.
결측치를 적절히 처리해주기만 하면 pd.get_dummies() 함수 사용이 가능합니다.
(이 데이터에 대한 상세한 결측치 처리 과정은 아래의 링크를 참고하시길 바랍니다.)
https://sjkoding.tistory.com/7
01. Dacon, 펭귄 몸무게 예측 경진대회 [데이콘 베이직 Basic] 참가 코드[18위 / 684명, score : 275.71371(RMSE
저는 오늘 처음으로 Dacon AI경진대회를 참가해보았습니다. 주제는 펭귄 몸무게 예측으로, 머신러닝 입문자를 위한 Basic 대회입니다. (작성일 기준, 저한테 맞는 수준입니다 ㅎ) https://dacon.io/competit
sjkoding.tistory.com

결측치가 모두 제거되었습니다.
이제 pd.get_dummies() 함수 사용이 가능해졌습니다. 그 전에 'Sex'컬럼에 대한 값은 MALE은 1, FEMALE은 0으로 지정해주었기 때문에 One-Hot 인코딩이 진행되지 않습니다.
이젠 모든 준비가 완료되었습니다. 위에서 미리 보여드린 대로 코드를 실행하고 결과를 확인해보시길 바랍니다!
One-Hot 인코딩은 범주형 데이터에 있어 가장 많이 활용되는 기법이므로 알아두시면 유용합니다!
2023.11.09 추가:
AI경진대회에서 test셋에 get_dummies()를 적용시키게 되면 Data Leakage 부정행위에 걸립니다. "test셋은 볼 수 없다"가 가정이고 실제 상황에서 하나의 데이터가 들어올 때 잘 처리할 수 있는지를 겨루는 대회이기 때문입니다.
따라서 sklearn.preprocessing모듈의 OneHotEncoder를 사용하여 train셋에 대해 fit을 해주시고 테스트셋에 대해 transform을 진행하시면 되겠습니다. 이렇게 되면 test셋을 보지 않고 train셋의 정보를 기반으로 변환이 이루어지기 때문에 부정행위 가 아닙니다.
감사합니다.
-sjkoding-