
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 연산량 감소
- SQL
- BFS
- pytorch
- 인접행렬
- skip connection
- numpy
- 식별자
- Inductive Bias
- dp
- resnet
- Depthwise Separable Convolution
- 인접리스트
- Two Pointer
- feature map
- get_dummies()
- bottleneck
- outer join
- 엔터티
- 그래프
- 1x1 Convolution
- depthwise convolution
- 데이터모델링
- 정규화
- mobilenet
- SQLD 후기
- 백준
- SQLD
- dfs
- CROSS JOIN
- Today
- Total
SJ_Koding
[LLM] Selective Reflection-Tuning 요약 및 정리 (feat. Reflection Llama-3.1 70B 논란) 본문
[LLM] Selective Reflection-Tuning 요약 및 정리 (feat. Reflection Llama-3.1 70B 논란)
성지코딩 2024. 9. 10. 16:27
Selective Reflection Tuning
Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning (2024.06)
LLM Fine-tuning의 성능 향상을 위해 데이터 품질을 향상하려는 시도, 그리고 데이터 생성에 대한 다양한 방법론이 연구되어왔습니다. 하지만 이는 모두 학생모델(이하 Student, 주로 Llama-3.1 8B, Solar 10.8B 등등의 sLM급 모델)의 호환성을 고려하지 않았다는 것을 핵심으로 이야기합니다. 이는 즉 Student의 제한된 성능때문에 GPT4o등이 만들어낸 고품질 프롬프트로 fine-tuning을 진행하더라도 이를 모방할 수 없다라는 의미로 받아들여집니다. 저는 현재 GPT4o-mini 로 생성해낸 데이터셋으로 fine-tuning을 진행하고 있으나, 해당 성능을 따라가진 못합니다. 어떻게 보면 당연하지만 이 현상을 크게 완화할 수 있는 기법으로 파악되어 추후 적용시켜볼 예정입니다.
이를 위해 교사모델(이하 Teacher, 주로 GPT-4o, Claude와 같은 고품질 초대형모델)이 데이터 개선을 위한 *Reflection을 진행하고 Student는 자신에게 맞는 데이터를 선택하는 기능을 통해 데이터를 자동으로 정제하는 기능을 Selective Reflection Tuning의 이름으로 소개합니다.
*Reflection:
- 모델이 기존의 명령어와 응답을 검토하고 개선하는 과정을 의미합니다.
- Teacher은 주어진 데이터를 보고 명령어나 응답이 얼마나 복잡한지, 명확한지, 또는 더 나은 방식으로 제공될 수 있는지를 분석합니다.
- 이 과정을 통해 모델은 데이터를 더 효과적이고 학습 가능한 형태로 개선합니다. 예를 들어, 모호한 명령어를 더 구체적으로 수정하거나, 불충분한 응답을 더 자세하고 관련성 있게 바꿉니다.
결과적으로 Student의 성능을 고려하고 잘 맞는, 즉 호환이 잘 되는 데이터를 만들 수 있으며 이는 데이터 추가 수집이 필요없으며 이로인해 fine-tuning 자체 성능을 개선할 수 있다는 점이 메리트입니다.
HOW?
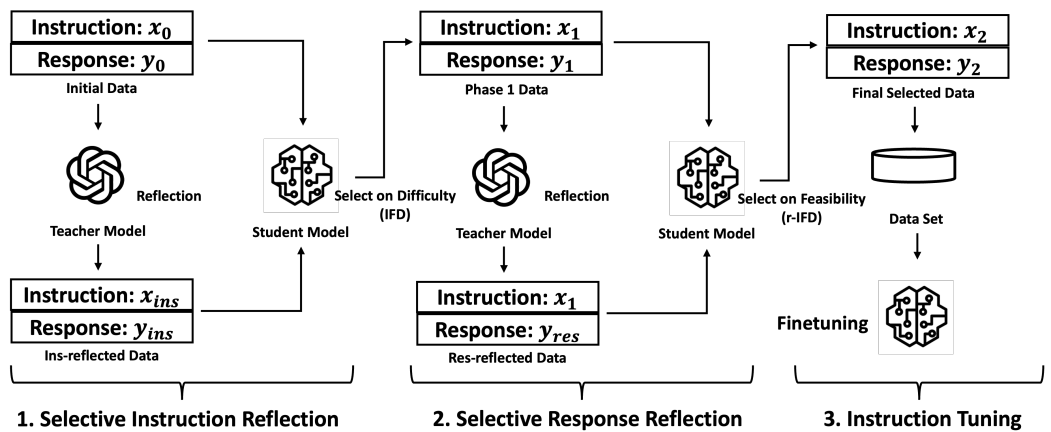
위 그림을 보면 크게 3단계로 구성되어있습니다.
1. Selective Instruction Reflection
Input 으로 가장 초기의 프롬프트 쌍($x_0, y_0$)이 주어집니다. 이를 Teacher에 넣고 새로운 프롬프트를 생성합니다. 이때 새로운 프롬프트를 생성하기 위한 프롬프트는 아래와 같습니다.

위 프롬프트를 한글로 정리하면 아래 더보기와 같습니다.
우리는 주어진 명령어의 품질과 관련된 몇 가지 질문에 답해주길 원합니다.
1. 이 명령어가 왜 좋지 않은지 분석하세요. 먼저, 다음 기준에 따라 명령어를 분석하세요:
- 주제의 복잡성
- 요구되는 세부 사항의 수준
- 필요한 지식
- 명령어의 모호성
- 논리적 추론 또는 문제 해결이 포함되는지 여부
그런 다음, 주어진 명령어에 대한 응답이 왜 좋지 않은지 다음 기준을 바탕으로 분석하세요:
- 도움이 되는지
- 관련성
- 정확성
- 세부 사항의 수준
마지막으로, 이 나쁜 명령어가 어떻게 나쁜 답변으로 이어졌는지 분석하세요.
2. 제공한 이유에 따라 새롭고 완전한 명령어를 생성하세요. 이 명령어는 복잡하고 직접적으로 답변하기 어려워야 하며, 원래의 명령어와 관련은 있지만 독립적이어야 합니다. 원래 명령어를 알지 않고도 답변할 수 있어야 하며, 다음 형식으로 작성하세요:
[New Instruction]
새로운 명령어
[End]
3. 새롭게 생성된 명령어에 가능한 한 자세하게 답변하세요. 다음 형식으로 작성하세요:
[New Answer]
새로운 답변
[End]
위 프롬프트와 같이 Teacher는 주어진 데이터를 Reflection하여 Instruction을 개선하고 개선된 데이터는 Ins-reflected Data로 표현되고있습니다. 그리고 새로운 Instruction와 Response는 각각 $x_ins, y_ins$로 표기되고 있네요.
Student는 새로 만들어진 데이터를 IFD(Instruction-Following Difficulty)점수를 통해 평가하고, 난이도가 적합한지에 따라 데이터 ($x_1, y_1$)를 선택합니다.
IFD는 한 마디로 주어진 instruction이 얼마나 어려운지를 측정하는 평가지표입니다. Student모델의 output의 토큰의 확률분포로 구해집니다. 수식은 아래와 같습니다.
$f_{\theta}(x) = \prod_{i=1}^{n} f(x[i] \mid x[1], \dots, x[i-1])$
: 각 token ($x[i]$)을 차례대로 예측하며, 이전 token들의 정보를 조건으로 다음 token의 확률을 예측하는 수식
$L_{\theta}(y \mid x) = -\frac{1}{n} \sum_{i=1}^{n} \log f_{\theta}(y \mid x)$
: Log-Likelihood
$\text{IFD}_{\theta}(y \mid x) = \frac{\text{ppl}(y \mid x)}{\text{ppl}(y)} = \exp \left( L_{\theta}(y \mid x) - L_{\theta}(y) \right)$
: IFD, instruction $x$가 response $y$에 미치는 영향을 측정, instruction이 있을 때의 난이도와 없을 때의 난이도를 비교합니다.
$ppl(y|x)$는 주어진 instruction $x$에서 response $y$를 예측하는 모델의 perplexity입니다. 낮을 수록 더 잘 예측하고 있는 것을 의미합니다. 당연히 $ppl(y)$는 instruction이 없는 상태에서 response y를 예측하는 것이겠죠?
두 perplexity를 비교하여 IFD점수를 구하는데, 이는 Log-Likelihood의 차이를 통해 계산됩니다. 해당 값이 높을 수록 instruction이 response을 잘 예측하는 데에 더 어려움을 겪는 것을 의미하며, 명령어의 난이도가 높다는 것을 나타냅니다.
즉, IFD가 높으면 instruction을 따르는 것이 어려운 것입니다. 해당 IFD의 score를 통해 앞서 말했듯 $x_1, y_1$을 선택합니다.
이때, IFD가 가장 높은 데이터를 선택합니다. IFD가 높다는 것은 해당 instruction이 Student에게 response를 생성하는데 더 어려움을 준다는 것을 의미하며, 해당 instruction이 Student에게 더 어렵다는 것을 시사한다라고 저자는 말했습니다.
이는 즉 Student에게 더 복잡하고 학습할 가치가 있는 데이터라고 해석할 수 있을 것 같습니다.
2. Selective Response Reflection
앞서 구한 ($x_1, y_1$)가 Teacher에 입력됩니다. 이때 저자는 $x_1$이 Student에게 어렵다고 IFD로써 보장되지만, 그에 따른 response $y_1$은 여전히 최적화되지 않았을 수도 있다 는 문제를 제기합니다. 이를 위해 Teacher은 response에 대한 reflection을 수행하여 개선된 응답 ($y_res$)을 생성합니다. 해당 데이터는 Res-reflected Data로 표기됩니다.
해당 단계에서 단순히 instruction의 난이도만 측정하는 IFD에서 더 나아가, r-IFD(Reversed Instruction-Following Difficulty)라는 새로운 지표를 추가합니다. 이는 response를 기반으로 instruction을 얼마나 쉽게 유추할 수 있는지 평가합니다.
낮은 r-IFD점수는 Student가 response를 통해 instruction을 더욱 쉽게 유추할 수 있음을 나타내며, 이는 해당 데이터가 Student에게 학습하기 Feasibility하다는 뜻입니다.
따라서 Student는 r-IFD 점수를 사용하여 response가 학습 가능성이 있는지(Feasibility)를 평가합니다. 그 결과 최종적으로 선택된 데이터 ( $ x_2, y_2 $ )가 생성됩니다.
저자는 r-IFD가 낮을수록 더 학습에 적합한 샘플이라고 판단하였습니다. $(x_1, y_1)$은 IFD가 가장 높은, 어려운 것을 택했지만 r-IFD는 왜 가장 낮은것을 택할지 궁금했습니다.
유추한 바로는 어려운 instruction을 통해 instruction이해능력을 키우면서도 이를 잘 이해하고 쉽고 명확한 response를 생성하도록 하는 것 같습니다.
Selective Response Reflection에 사용된 프롬프트는 아래와 같습니다.

위 프롬프트를 한글로 정리하면 아래 더보기와 같습니다.
**시스템 프롬프트**
당신은 주어진 명령어에 대한 응답의 품질을 확인하는 데 있어 도움이 되며, 정확하지만 까다로운 조력자입니다.
**사용자 프롬프트**
```
[Instruction]
명령어
[The Start of Answer]
응답의 시작
[Answer]
응답
[The End of Answer]
응답의 끝
```
우리는 주어진 명령어에 대한 응답의 품질과 관련된 몇 가지 질문에 답해주길 원합니다:
1. 왜 이 응답이 주어진 명령어에 대해 좋지 않은가? **도움이 되는지**, **관련성이 있는지**, **정확성**, 그리고 **세부 사항의 수준**을 기준으로 분석해 주세요.
2. 제공한 이유를 바탕으로, 더 나은 새로운 응답을 생성해 주세요. 새로운 응답은 완전하고 가능한 한 세부적으로 작성해야 하며, 다음 형식으로 작성해 주세요:
```
[Better Answer]
더 나은 응답
[End]
```
3. Instruction tuning
생성된 $(x_2, y_2)$를 통해 파인튜닝을 진행합니다. 여기서 볼 수 있듯이 별도의 데이터를 추가수집하지 않고 기존의 데이터를 변환하기만 해도 큰 성능 향상을 보였다는 점에서 인상깊었습니다.
(Result 생략!)
Limitations
저자가 인정한 한계점은 아래와 같습니다.
1. Student가 바뀔 때 마다 새롭게 적용하여 데이터셋을 꾸며야 한다는 점입니다. 모델마다 선택되는 데이터가 달라지기 때문입니다.
2. 새로운 모델마다 통계를 어쨋든 다시 계산해야 한다는 점입니다.
즉, 해당 방법론이 Student에 맞는 데이터 생성을 가능하게 한다는 장점이 있지만, 모델이 달라질 때 마다 데이터를 다시 계산해야 하는 비효율성이 한계점으로 인정했습니다.
파인튜닝을 지금껏 바닐라하게만 진행했던 것 같습니다. 이런 최신 기법들을 더욱 공부하고 프로젝트에 적용시킬 수 있는 능력을 키워야겠다고 느꼈습니다.
성능 미쳤다! (수정 참고)
Hugging Face사이트의 Trending순위를 보던 중 갑자기 1위를 달성한 모델을 확인했습니다.

Meta 사의 Llama-3.1 모델 앞에 Reflection이라는 키워드를 보고 궁금증이 생겨 확인해보았더니 벤치마크 스코어가 말도 안되게 높았습니다.

엄청난 벤치마크 스코어를 보고, Reflection Tuning이 대체 뭐길래 라는 궁금증이 생겼습니다.
+) 수정:
https://x.com/shinboson/status/1832933753837982024/photo/2
해당 포스트를 보면 위 벤치마크 결과는 잘못되었다고 비판하고있습니다.
Artificial Analysis라는 외국 업체에서 독립적으로 자체 평가를 한 결과 기존 Meta-Llama-3.1-70B보다 오히려 낮은 스코어를 기록했다고 합니다.

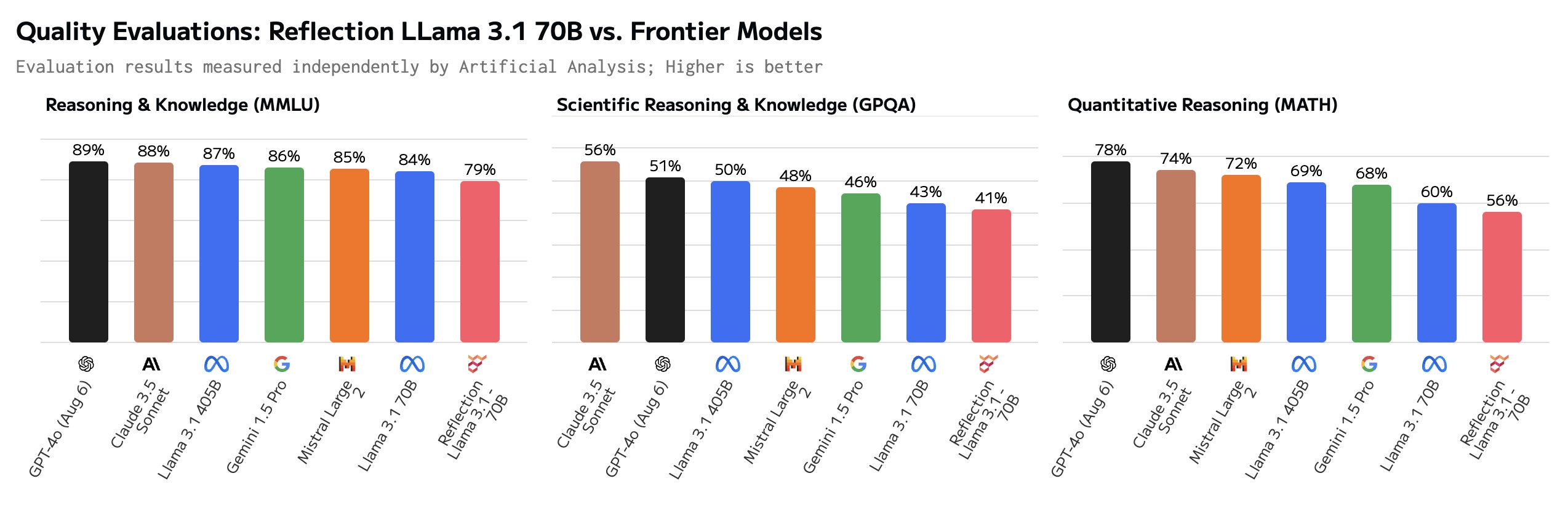
결정적으로 Reflection Llama-3.1 70B가 크게 부정적인 평가를 받는 이유

제가 hugging face 커뮤니티에 직접 올린 문의글에 대한 답변입니다. 왜이렇게 부정적인지에 대한 글이었는데 위와 같은 행동을 벌였다고 합니다.
일단 직접 사용해보려고 GGUF버전을 다운로드 하여 원본 4Q-L모델과 비교하였습니다. 그 결과 성능이 확실히 높아진 것을 알 수 있는데, 추론 과정에서도 reflection 알고리즘을 수행합니다. 사용할때 주어진 system prompt사용을 권유했고 문장 끝에 Think carefully등과 같은 프롬프트도 포함시켰습니다.
성능 자체는 향상된 것으로 보이지만 위와같은 언행들로 부정적인 평가를 받고 있는 것 같습니다.
+ 자료를 제공해주신 HEY, GERONIMO님 감사드립니다.
'세계 최고 오픈 소스 모델' 제작자, 사기 논란에 "앞서나갔다"고 사과 - AI타임스
\"세계 최고의 오픈 소스 모델\" 사기 논란에 휩싸였던 하이퍼라이트의 CEO가 \"너무 앞서나갔다\"라고 사과했다. 사실상 과장 홍보라는 것을 인정한 셈이다.맷 슈머 하이퍼라이트 CEO는 11...
www.aitimes.com
결국 제작자도 잘못을 인정한 해프닝이 되었습니다. 역시나 보이는대로 모든것을 믿어버리면 안되는군요,, 저는 처음 GPT, Claude를 뛰어넘는 스코어를 보고 추론 해볼때까지 설레기만 했었습니다. (다들 그런가요?)
LLM 초보자 입니다. 틀린 내용이 있을 수 있으며 지적 사항과 의논할 부분 언제든 댓글 남겨주세요!
감사합니다.


