
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터모델링
- 식별자
- dp
- mobilenet
- Inductive Bias
- CROSS JOIN
- numpy
- 인접리스트
- get_dummies()
- bottleneck
- depthwise convolution
- dfs
- SQLD 후기
- resnet
- pytorch
- SQL
- 정규화
- 연산량 감소
- feature map
- 엔터티
- 백준
- skip connection
- 인접행렬
- outer join
- Two Pointer
- BFS
- 1x1 Convolution
- Depthwise Separable Convolution
- 그래프
- SQLD
- Today
- Total
SJ_Koding
Depthwise (Separable) Convolution의 설명 및 Pytorch 예시 본문
- 부제: ConvNeXt이해하기 3편 -
Xception에서 제시된 컨셉으로 유명해졌다. 쉽게 이해할 수 있다.
먼저 Depthwise convolution을 알기 전에 일반적인 Convolution 연산을 알아보자.
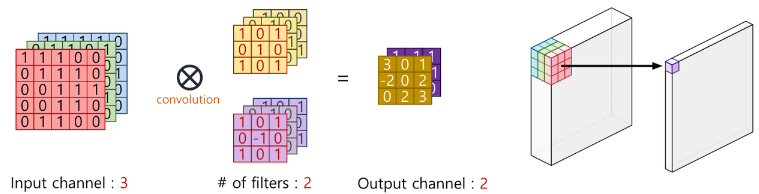
기본적인 개념으로 Input channel수는 filter channel수와 동일해야하고, filter의 개수는 output channel이 된다. 이것이 일반적인 convolution의 본질이다. 3x3 filter를 기준으로 모든 채널과 인접한 3x3 feature들을 하나의 scalar값으로 바꾸게 된다.
Depthwise convolution
Depthwise convolution은 convolution 연산을 '채널별로 독립적으로' 수행한다. 즉 다음 그림과 같다.


그림을 보면 R, G, B채널의 Color Image가 있다고 가정할 때, 각 채널마다 독립적으로 각기 다른 필터를 적용시켜 새로운 feature map을 만들어낸다. 기존에는 각 채널마다 독립적으로 진행하지 않고, 하나의 필터로 모든 채널의 연산을 수행한 것과 차이점이 있다.
Pointwise convolution
사실 Depthwise convolution은 기법중 하나이며 실제 사용시에는 Pointwise convolution과 함께 사용된다. 주 목적은 연산량 감소이다. 극한의 경량화를 시도한 MobileNet에서 대표적으로 사용된 기법이다.
Pointwise convolution은 채널별로 독립적으로 depthwise conv연산이 수행된 feature map에서, 1x1 convolution으로 채널을 압축하는 것을 의미한다. 1x1 convolution의 역할과 매우 유사하다. 아래 그림을 참고하자.
(1x1 convolution에 대한 설명은 아래 포스팅을 참고하자)
1x1 convolution의 설명 및 Pytorch 예시
부제: - ConvNeXt 이해하기 1편 - 1x1 convolution 1x1 convolution은 필터 사이즈가 1x1라는 것을 의미한다. 즉, feature map의 feature 하나(Image Input기준으로 픽셀 하나) 에 대해 convolution 연산을 진행한다. 1x1 convol
sjkoding.tistory.com

왜 써?! depthwise + pointwise = depthwise seperable convolution
depthwise convolution과 pointwise convolution을 단계적으로 사용한 것이 depthwise seperable convolution이며 이는 연산량 감소에 유리하다. 즉 일반적인 convolution연산을 진행하는 것 보다 위와 같이 진행하는 것이 더 연산량을 최소화 시킬 수 있다는 것이다.
연산량 차이
IC : Input channel
OC: Output channel
F : Filter size
D : Feature map size
일반 Convolution의 연산량
IC * OC * F * F * D * D
Depthwise seperable convolution 연산량
IC * F * F * D * D(depthwise convolution) + IC * OC * D * D (pointwise convolution)
둘을 나누어보자.
(IC*F*F*D*D + IC*OC*D*D ) / (IC*OC*F*F*D*D) = 1/OC + 1/F*F 일반적으로 OC가 D보다
훨씬 크므로 filter size 즉 K=3일경우 1/9배 연산량을 감소시킬 수 있다.
Pytorch 구현 차이
stadard convolution
standard_conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
depthwise separable convolution
class DepthwiseSeparableConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=1):
super(DepthwiseSeparableConv, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding, groups=in_channels)
# 이 위에 groups=in_channels 가 차이!
self.pointwise = nn.Conv2d(in_channels, out_channels, 1)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
# 예시로 in_channels=3, out_channels=64, kernel_size=3을 사용
depthwise_separable_conv = DepthwiseSeparableConv(3, 64, 3)'Deep Learning' 카테고리의 다른 글
| ConvNeXt (A ConvNet for the 2020s, facebook) 논문 리뷰 (0) | 2024.04.04 |
|---|---|
| manifold와 Inverted Bottleneck의 설명 (1) | 2024.04.04 |
| Grouped convolution의 설명 및 PyTorch 예시 (1) | 2024.04.03 |
| Bottleneck 구조(resnet)의 설명 및 Pytorch 예시 (0) | 2024.04.03 |
| 1x1 convolution의 설명 및 Pytorch 예시 (1) | 2024.04.03 |



