
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 그래프
- pytorch
- depthwise convolution
- 백준
- dp
- feature map
- bottleneck
- 정규화
- outer join
- Two Pointer
- dfs
- get_dummies()
- CROSS JOIN
- Inductive Bias
- numpy
- SQLD
- resnet
- Depthwise Separable Convolution
- 엔터티
- mobilenet
- skip connection
- SQL
- SQLD 후기
- 1x1 Convolution
- 식별자
- 인접행렬
- BFS
- 데이터모델링
- 연산량 감소
- 인접리스트
- Today
- Total
SJ_Koding
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 1편, Introduction 본문
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 1편, Introduction
성지코딩 2024. 4. 22. 16:46해당 논문을 보면서 LLM 연구의 큰 흐름을 대강이라도 파악할 수 있었다. 최근에 LLaMA2에 비해 비약적으로 성능을 향상시킨 (LLaMA3-8B가 LLaMA2-70B를 이김;;) LLaMA3오픈소스가 hugging face에 공개되면서 더욱 궁금증이 생겼다.
LLM을 할 일이 생겼는데, Vision은 잠시 접어두고 LLM 공부에 투자해야겠다.
LLaMA모델은 Meta에서 발표한 모델로 적은 파라메터 수(7B)와 대규모 어디서든 접근 가능한 데이터셋(수조 개 token)만을 사용하여 SOTA를 달성한 모델이다. 사전 지식이 부족하기 때문에, Introduction 만큼은 한 줄 한 줄 자세히 살펴보고, 인용된 중요한 논문을 대강 훑어 정리해본다.
Introduction
Large Languages Models (LLMs) trained on massive corpora of texts have shown their ability to perform new tasks from textual instructions or from a few examples (Brown et al., 2020).
대규모 텍스트 코퍼셋으로 학습된 LLMs는 textual instructions나 few texamples에서 새로운 작업을 수행할 수 있는 능력을 보여줬다. (GPT-3에 대한 이야기)
These few-shot properties first appeared when scaling models to a sufficient size (Kaplan et al., 2020), resulting in a line of work that focuses on further scaling these models (Chowdhery et al., 2022; Rae et al., 2021).
이런 few-shot 속성은 모델을 충분한 크기로 scaling할 때 처음 나타났으며(scaling laws), 그 결과 이러한 모델을 더욱 scaling하는 데 초점을 맞춘 연구가 진행되었다. (palm, Minerva)
부록, Scaling laws for neural language models
OpenAI 논문, Transformer기반 LM을 대상으로 경험적인 결과를 발견.
- OpenAI의 연구에 따르면, Transformer 기반의 언어 모델 성능은 주로 모델 파라미터 수(N), 데이터 셋 크기(D), 그리고 필요한 컴퓨팅 양(C)에 의존함
- 모델의 구조적 hyper-parameter (depth, width)의 영향은 상대적으로 매우 약함
- 성능은 N, D, C 각각에 대해 power-law 관계를 보이며, 어떤 scale factor도 bottle-neck을 일으키지 않는 한 성능 개선이 예측 가능함
- N과 D를 동시에 확장할 경우 성능이 개선되지만, N 또는 D중 하나만 증가시킬 경우 고정된 요소가 성능 패널티를 야기하여 성능 향상이 줄어듦. 예를 들어 N이 8배 증가하면 D도 약 5배 증가해야함(성능 패널티는 (N^0.74)/D 에 의존)
- 학습 초기 곡선을 분석하면 장기간 학습을 통해 달성할 수 있는 loss를 예측할 수 있음
- 큰 모델은 작은 모델보다 샘플 효율이 더 높아, 적은 최적화 단계와 더 적은 데이터로 같은 수준의 성능을 달성할 수 있음
- 고정된 C 내에서 N과 D에 대한 제한이 없을 때, Very Large Model을 학습하면 가장 성능이 좋다. (추후 반박)
These efforts are based on the assumption that more parameters will lead to better performance.
이 노력들은 많은 파라메터가 더 나은 성능을 이끌어낸다는 가정을 기반한다.
However, recent work from Hoffmann et al. (2022) shows that, for a given compute budget, the best performances are not achieved by the largest models, but by smaller models trained on more data.
하지만 주어진 compute budget 에서 최고의 성능은 가장 큰 모델이 아니라 더 많은 데이터로 훈련된 더 작은 모델이었다.
부록: Training Compute-Optimal Large Language Models (Hoffmann et al.)
- Scaling laws을 반박(?)하는 Compute-Optimal Model 제안
- C가 고정되어있을 때, optimal 한 N과 D와의 관계가 존재함
- (C: Compute budget, N: Num of params, D: Num of data(tokens))
- Scaling laws 결과와 달리 model performence를 위한 Model Size와 Training Tokens와의 관계는 거의 1:1의 weights를 가짐
- C내에서 N과 D간의 관계를 찾기 위해 수 많은 실험을 진행 (약 400여개의 LM)
- model size (params): 70M ~ 16B
- tokens: 5B ~ 500B
- C내에서 N과 D간의 관계를 찾기 위해 수 많은 실험을 진행 (약 400여개의 LM)
- 이전에 DeepMind 에서 공개한 LLM Gopher 에 사용된 C로부터, Gopher의 optimal model은 현재보다 4배 더 작은 N과, 4배 더 많은 D를 사용해야 한다는 것을 예측함
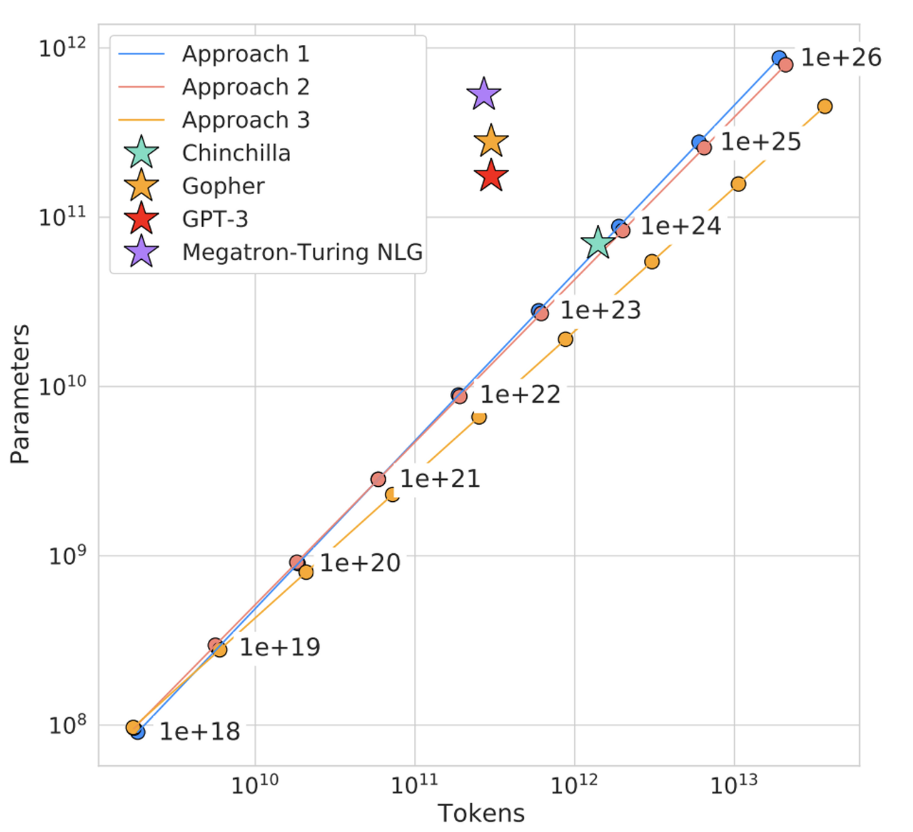
The objective of the scaling laws from Hoffmann et al. (2022) is to determine how to best scale the dataset and model sizes for a particular training compute budget.
compute-optimal논문에서 scaling laws의 목적은 정해진 compute budget에 맞게 데이터셋과 모델 크기를 잘 scale하는 법을 결정하는 것이다.
However, this objective disregards the inference budget, which becomes critical when serving a language model at scale.
하지만 이는 LLM을 제공할 때 중요해지는 inference budget을 무시한다.
In this context, given a target level of performance, the preferred model is not the fastest to train but the fastest at inference, and although it may be cheaper to train a large model to reach a certain level of performance, a smaller one trained longer will ultimately be cheaper at inference.
이런 문맥에서, 목표하는 성능이 주어졌을 때 선호하는 모델은 train 속도가 가장 빠른 모델이 아니라 inference 속도가 가장 빠른 모델이며, 특정 수준에 도달하기 위해 큰 모델을 훈련하는 것이 더 저렴할 수 있지만 궁극적으로는 더 오래 훈련된 작은 모델이 inference 비용이 더 저렴할 것이다.
For instance, although Hoffmann et al. (2022) recommends training a 10B model on 200B tokens, we find that the performance of a 7B model continues to improve even after 1T tokens.
예를 들어, 비록 호프만은 2000억 토큰과 100억짜리 모델을 추천하지만, 1T 토큰 이후에도 7B모델의 성능이 계속 향상되는 것을 확인했다.
The focus of this work is to train a series of language models that achieve the best possible performance at various inference budgets, by training on more tokens than what is typically used.
이 작업의 초점은 일반적으로 사용되는 것보다 더 많은 token으로 훈련하여 다양한 inference budgets에서 최상의 성능을 달성하는 일련의 LM을 훈련하는 것이다.
The resulting models, called LLaMA, ranges from 7B to 65B parameters with competitive performance compared to the best existing LLMs.
LLaMA라고 하는 결과 모델은 70억에서 650억 개의 파라메터 범위에서 현존하는 최고의 LLM과 비교하여 경쟁력 있는 성능을 제공한다.
For instance, LLaMA-13B outperforms GPT-3 on most benchmarks, despite being 10× smaller.
예를 들어, LLaMA-13B는 10배 더 작음에도 불구하고 대부분의 벤치마크에서 GPT-3보다 성능이 뛰어나다.
We believe that this model will help democratize the access and study of LLMs, since it can be run on a single GPU.
이 모델은 단일 GPU에서 실행할 수 있기 때문에 LLM에 대한 접근과 학습을 대중화하는 데 도움이 될 것으로 믿는다.
At the higher-end of the scale, our 65B-parameter model is also competitive with the best large language models such as Chinchilla or PaLM-540B.
규모가 더 큰 경우, 65B-parameter 모델은 Chinchilla 또는 PaLM-540B와 같은 최고의 LLM과도 경쟁력이 있다.
Unlike Chinchilla, PaLM, or GPT-3, we only use publicly available data, making our work compatible with open-sourcing, while most existing models rely on data which is either not publicly available or undocumented (e.g. “Books – 2TB” or “Social media conversations”). There exist some exceptions, notably OPT (Zhang et al., 2022), GPT-NeoX (Black et al., 2022), BLOOM (Scao et al., 2022) and GLM (Zeng et al., 2022), but none that are competitive with PaLM-62B or Chinchilla.
대부분의 기존 모델이 공개적으로 사용 가능하지 않거나 문서화되지 않은 데이터(예: "도서 - 2TB" 또는 "소셜 미디어 대화")에 의존하는 반면, 저자는 공개적으로 사용 가능한 데이터만 사용하므로 오픈 소싱과 호환된다. OPT, GPT-NeoX(Black 외, 2022), BLOOM, GLM등 몇 가지 예외가 있지만 PaLM-62B나 Chinchilla와 경쟁할 만한 것은 없다. (기존에 비해 눈에 띄게 많이 사용하지 않았거나 다른 데이터들에 의해 묻혔다란 의미로 유추)
In the rest of this paper, we present an overview of the modifications we made to the transformer architecture (Vaswani et al., 2017), as well as our training method. We then report the performance of our models and compare with others LLMs on a set of standard benchmarks. Finally, we expose some of the biases and toxicity encoded in our models, using some of the most recent benchmarks from the responsible AI community.
이 논문의 나머지 부분에서는 transformer 아키텍처에 적용한 수정 사항(Vaswani 외, 2017)과 훈련 방법에 대한 개요를 소개한다. 그런 다음 모델의 성능을 보고하고 일련의 표준 벤치마크에서 다른 LLM과 비교한다. 마지막으로, 책임감 있는 AI 커뮤니티(hugging face로 유추)의 최신 벤치마크를 사용하여 모델에 인코딩된 biases과 toxicity(LLM에서 정치, 성희롱 등 부정적인 토큰들을 의미하는 듯) 중 일부를 노출한다.
Introduction 요약
1. 모델 크기랑 데이터 크기를 늘린다고만해서 절대적으로 최상의 성능이 아니다.
2. 오히려 모델을 작게하고 데이터 크기를 늘리는게 낫다.
3. 기존에는 train budget만 따졌지만 실질적으로 inference budget이 중요하다.
4. 우리는 모델 파라메터수를 적게 가지고 몇 조개 이상의 토큰을 사용하여 SOTA를 달성했다.
5. 데이터는 누구나 접근가능한 public데이터를 활용했다.
'LLM' 카테고리의 다른 글
| LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 3편, Main Result (0) | 2024.04.24 |
|---|---|
| LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 2편, Approch (0) | 2024.04.23 |
| GPT3에 대해 이해해보자 (GPT 3편) - Language Models are Few-Shot Learners (0) | 2024.03.21 |
| GPT-2에 대해 이해해보자 (GPT 2편) (0) | 2024.03.20 |
| GPT-1에 대해 이해해보자 (GPT 1편) (0) | 2024.03.20 |



