
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- SQLD
- Depthwise Separable Convolution
- Inductive Bias
- numpy
- outer join
- SQL
- 백준
- feature map
- 인접행렬
- SQLD 후기
- dp
- 식별자
- CROSS JOIN
- 정규화
- get_dummies()
- mobilenet
- 그래프
- bottleneck
- 인접리스트
- 연산량 감소
- pytorch
- Two Pointer
- 엔터티
- depthwise convolution
- BFS
- skip connection
- resnet
- 데이터모델링
- 1x1 Convolution
- dfs
- Today
- Total
SJ_Koding
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 3편, Main Result 본문
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 3편, Main Result
성지코딩 2024. 4. 24. 13:48LLaMA의 성능 비교실험 결과를 자세히 기술한다. 테스크별로 하위 섹션을 나누었으며 어떤식으로 실험을 구성했는지 잘 설명되어있다. LLaMA가 당시 왜 각광받았는지 알 수 있는 섹션인 것 같다.
Introduction, Approach가 궁금하면 아래 링크를 클릭!
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 2편, Approch
이전 글에 이어 Approch에 대한 내용이다. 이전글과 다르게 지금부터는 핵심만 요약한다. LLaMA-1의 Pre-training, Architecture, Optimizer, Efficient implementation을 정리한다. LLM 모델에서 어떤식으로 데이터셋을
sjkoding.tistory.com
3. Main Result
LLaMA는 GPT-3에 따라, zero-shot / few-shot learning을 고려하고 총 20개의 Benchmark에 대한 결과를 제시했다.
이때, 공개되지 않은 모델들인 GPT-3, Gopher, Chinchilla, PaLM, GPT-J, GPTNeo등 과 비교하고 Section 4에서는 LLaMA를 OPT-IML 및 FlanPaLM과 같은 명령어 조정 모델과 간략한 비교도 수행한다.
LLaMA는 free-form generation task 및 multiple choice task를 통해 평가하며 multiple choice task에서는 주어진 context를 기반으로 주어진 option 중에서 가장 적합한 completion을 선택하는 것이다. 즉, 가장 likelihood가 높은 option을 선택한다.
LLaMA는 대부분의 데이터셋에서 completion의 likelihood를 문자 수로 normalize하여 사용했다. 하지만 일부 데이터셋(OpenBookQA, BoolQ)에서는 completion의 likehood를 "Answer:" context에서의 likelihood로 정규화하여 선택한다:
P(completion|context) / P(completion | "Answer:")
3.1 Common Sense Reasoning (상식 퀴즈)

LLaMA는 8개의 common sense reasoning의 벤치마크인 BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, ARC easy and challenge, OpenBookQA를 고려했다.
해당 데이터셋들은 Cloze task와 Winograd스타일의 task를 포함하며, multiple choice문제도 포함된다. 여기서 LLaMA는 자연어 처리 커뮤니티(paper with code or hugging face로 추정)에서 수행되는 것과 같은 zero-shot설정에서 평가를 진행했다.
Table 3에서 볼 수 있듯이, 다양한 크기의 LLaMA와 기존 모델들을 실험한 결과 거의 모든 벤치마크에서 Chinchilla-70B보다 성능이 우수하고 PaLM-540B를 능가한다. LLaMA-13B 모델 역시 10배 더 작음에도 불구하고 대부분의 벤치마크에서 GPT-3보다 성능이 우수한 것을 확인할 수 있다.
3.2 Closed-book Question Answering (학습된 데이터에만 의존하여 답변)

외부 문서에 접근할 수 없는 상황에서의 평가 벤치마크이다. 두 개의 벤치마크(Natural Questions, TriviaQA)에서 LLaMA-65B는 zero shot, few shot에서 최고의 성능을 달성했다.
더 중요한 것은 LLaMA-13B가 GPT-3와 ChinChilla와 비빌만한 성능임에도 5~10배 모델이 작다는 것에 경쟁력이 있다고 말한다. 이는 추론 시 단일 V100 GPU에서 실행이 가능하다는 점에서 큰 메리트로 생각한다.
3.3 Reading Comprehension(문장 이해력)
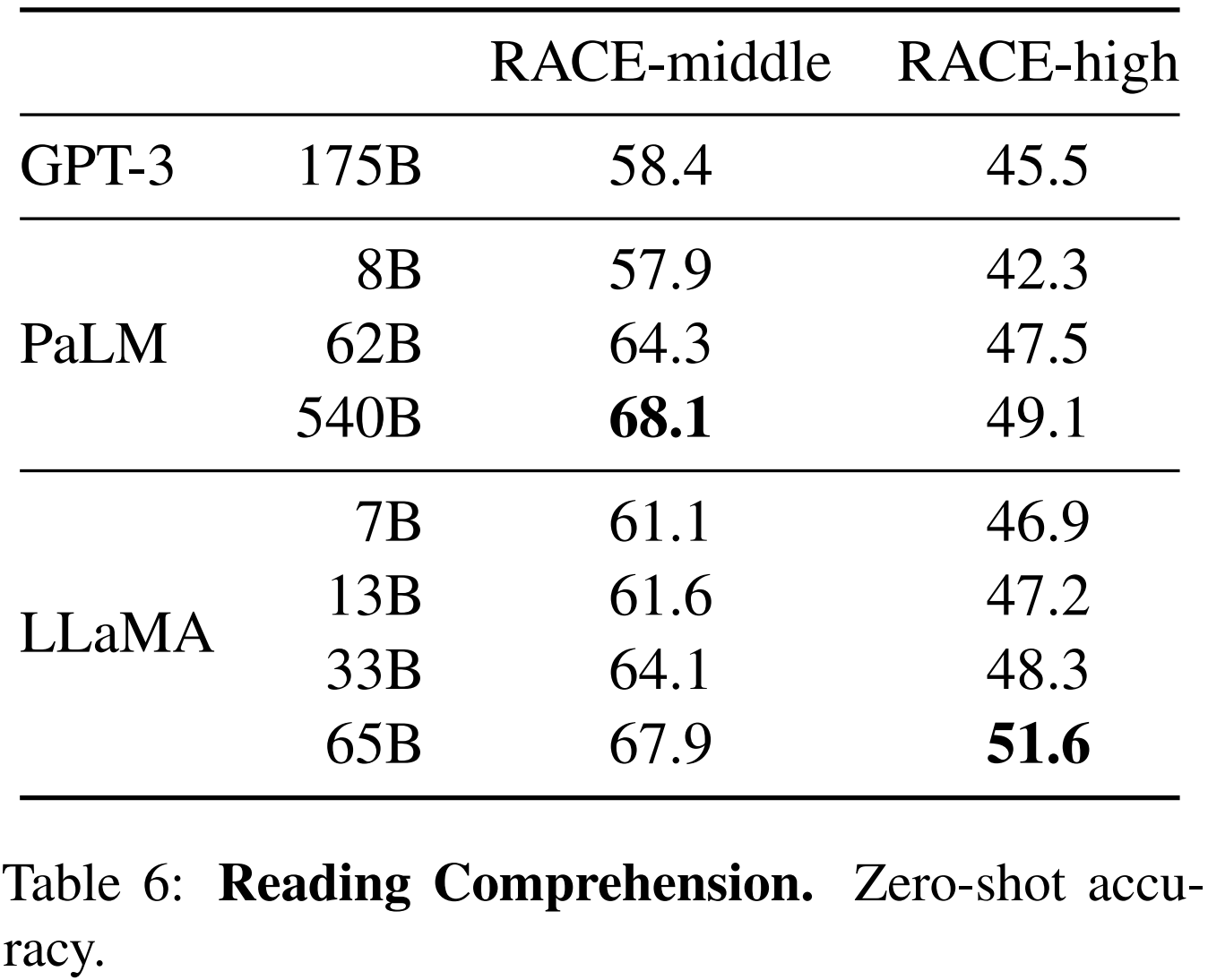
LLaMA는 Reading Comprehension 능력을 RACE 벤치마크로 평가했다. 해당 벤치마크는 중국 중고등학생을 대상으로 고안된 영어 독해력 시험에서 수집한 데이터셋을 이용한다. LLaMA-65B가 PaLM-540B와 경쟁력이 있고, LLaMA-13B는 GPT-3보다 몇 퍼센트 더 우수한 성능을 보였다.
3.4 Mathematical reasoning(수식 의미추론)

LLaMA는 Mathematical reasoning에 대해 MATH 및 GSM8k 벤치마크로 모델을 평가했다.
MATH는 12k개의 중고등학교 수학 문제로 구성된 LaTeX 데이터셋이며, GSM8k는 중학교 수학문제 세트이다.
여기서 Minerva모델은 ArXiv와 수학 웹페이지에서 추출한 385억개의 token으로 fine tuning된 PaLM계열 모델이다. 반면 PaLM이나 LLaMA는 수학 데이터로 fine tuning이 되지 않은 상태이다.
그럼에도 불구하고 GSM8k 벤치마크에서 LLaMA65B가 Minerva-62B보다 성능이 뛰어난 것으로 확인되었다. (MATH에서는 저조한 성적이지만 GSM8k에서 별도의 fine tuning없이 성능을 능가한 것에 주목할 필요가 있다.)
3.5 Code Generation(코드 생성)

LLaMA는 HumanEval과 MBPP벤치마크를 사용했다. 두 벤치마크는 모두 프로그램에 대한 몇 문장의 설명과 입출력 예시가 포함되어있다. (코테 양식을 떠올리자.) HumanEval에서는 function의 시그니처도 받으며, prompt는 natural code 형식으로 구성되어 text설명과 docustring의 test를 포함한다.
예를 들어 코테를 잘 푸냐? 를 테스트한다.
Table8에서 볼 수 있듯이, code데이터에 특별히 fine tuning되지 않은 기존의 언어 모델들인 PaLM과 LaMDA와 비교하여 모델들의 pass@1 점수를 볼 수 있는데, LLaMA는 비슷한 수의 파라메터를 가지는 다른 모델들보다 우수한 성능을 보이며 특히 13B파라메터 이상의 LLaMA는 137B파라메터의 LaMDA를 두 벤치마크에서 모두 뛰어넘었다.
또한 LLaMA 65B는 더 오래 훈련된 PaLM 62B보다도 우수한 성능을 보인다.
코드 생성에 대한 성능을 더 개선하기 위해 코드의 특정 token에 대해 튜닝하는 방법이 있는데, 이는 논문 범위에 벗어나므로 다루지 않았다고 한다.
3.6 Massive Multitask Language Understanding(코드 생성)

MMLU벤치마크 사용했다. 이는 인문학, STEM, 사회과학 등 다양한 지식 영역을 포괄하는 객관식 문항으로 구성되어있으며 5지선다형 환경에서 모델을 평가한다.
Table 9를 보면 다른 벤치마크 평가와 달리 유일하게 LLaMA가 뒤떨어지는 것을 볼 수 있는데, LLaMA에서 사용한 데이터셋에서 책과 학술 논문의 양이 제한적이었다라는 점을 인정했다.
이전 포스팅의 Approach에서 LLaMA의 학습 데이터를 볼 수 있는데, Chinchilla 혹은 PaLM은 2TB의 책으로 학습한 반면 LLaMA는 177GB에 불과하다.
3.7 Evolution of performance during training


Figure 2를 참고할 때, 대부분의 벤치마크에서 모델의 성능은 꾸준히 향상되고, 모델의 성능은 모델의 파라메터 수 즉 복잡성과 상관관계가 있는 것을 확인할 수 있다. (Figure 1 참고)
그러나 SIQA와 WinoGrande 벤치마크에서 예외사항을 볼 수 있는데, 이는 해당 벤치마크가 신뢰성이 떨어지는 것을 시사한다.
WinoGrande에서는 성능이 훈련 복잡도와 잘 상관되지 않으며 33B, 65B 모델이 훈련 중 유사한 성능을 보인다.
4편은 Instruction Finetuning에 대해 다룬다



