
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Two Pointer
- get_dummies()
- pytorch
- SQLD 후기
- bottleneck
- feature map
- Depthwise Separable Convolution
- 식별자
- CROSS JOIN
- depthwise convolution
- BFS
- dp
- 엔터티
- 정규화
- SQL
- mobilenet
- dfs
- 그래프
- numpy
- 인접행렬
- resnet
- 인접리스트
- 데이터모델링
- 연산량 감소
- Inductive Bias
- SQLD
- 1x1 Convolution
- 백준
- skip connection
- outer join
- Today
- Total
SJ_Koding
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 2편, Approch 본문
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 2편, Approch
성지코딩 2024. 4. 23. 17:21이전 글에 이어 Approch에 대한 내용이다. 이전글과 다르게 지금부터는 핵심만 요약한다. LLaMA-1의 Pre-training, Architecture, Optimizer, Efficient implementation을 정리한다. LLM 모델에서 어떤식으로 데이터셋을 구축하고, 얼만큼의 자원을 사용하는지, 어떤식으로 학습하는지를 파악할 수 있는 섹션이다. 해당 섹션을 리뷰하면서 대강 LLM의 전반적인 접근방식을 파악할 수 있었다.
LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 1편, Introduction
해당 논문을 보면서 LLM 연구의 큰 흐름을 대강이라도 파악할 수 있었다. 최근에 LLaMA2에 비해 비약적으로 성능을 향상시킨 (LLaMA3-8B가 LLaMA2-70B를 이김;;) LLaMA3오픈소스가 hugging face에 공개되면서
sjkoding.tistory.com
Approch
LLaMA는 PaLM, GPT-3의 방법론에 따르고 chincilla scaling laws를 따른다.
Pre-training Data
LLaMA-1은 어떤 데이터를 사용해서 학습되었을까?
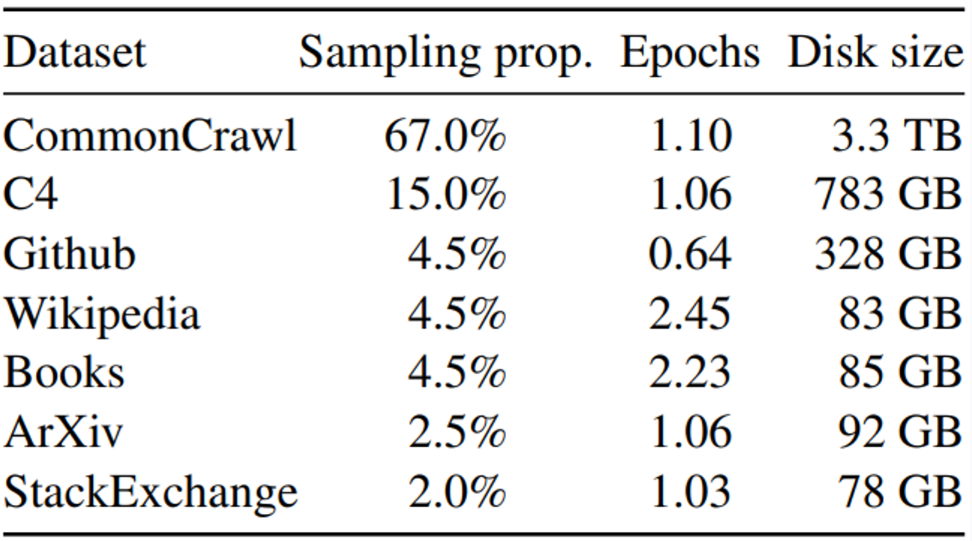
위 그림의 데이터셋을 혼합하여 제시된 비율만큼 사용했다. 이는 모두 공개적으로 접근 가능한 데이터셋이며, 위 데이터셋을 사용했을 때 1.4조개의 토큰을 사용한다. 그리고 아래는 논문에서 제시된 데이터셋(tokenizer포함)에 대한 설명이다.
- CommonCrawl Dataset
- 2017년부터 2020년까지 5개의 dump를 CCNet pipeline으로 처리
- 한 행 단위에서 중복을 제거하고 fastText 선형 분류기로 영어가 아닌 페이지 제거
- ngram으로 저품질 콘텐츠 필터링, 선형 모델로 reference로 분류되지 않은 페이지 폐기
- C4 Dataset
- Raffle et al. 이 2020년에 제시한 데이터셋
- C4의 전처리에는 중복 제거 및 언어 식별 단계도 포함
- CCNet pipeline과의 주요 차이점은 구두점 유무나 웹페이지의 단어 및 문장 수와 같은 휴리스틱에 의존하는 filtering 을 사용
- Github Dataset
- Google BigQuery에서 제공되는 공개 GitHub 데이터셋.
- 줄 길이, 영어/숫자 비율을 기반으로 한 휴리스틱으로 품질이 낮은 파일을 필터링
- 정규식으로 상용구 제거
- Wikipedia Dataset
- 2022년 6월부터 8월까지 라틴어 또는 키릴 문자를 사용하는 20개 언어의 덤프를 추가
- 하이퍼링크를 제거하기 위한 데이터 처리
- Gutenberg and Books3 Dataset
- 책을 포함하는 Gutenberg프로젝트와 LLM학습을 위한 public 데이터셋인 ThePile의 Book3 섹션의 두 가지 책 코퍼스
- 책 단위로 중복 제거를 수행해 90% 중복 제거
- ArXiv Dataset
- 과학적 데이터를 추가하기 위해 LaTex파일 처리
- Lewkowycz 논문에 따라 section 앞 부분과 reference 모두 제거
- tex파일에서 주석과 사용자가 작성한 inline확장 및 macro를 제거하여 논문 간 일관성 확보
- Stack Exchange Dataset
- 컴퓨터 과학, 화학분야의 Q&A가 있는 Stack Exchange(Stack overflow와 유사한 커뮤니티)의 dump 사용
- HTML 태그를 제거한 후, 답변의 점수별로 정렬
- Tokenizer
- BPE(Byte Pair Encoding) 사용
- 기존에 있던 단어를 분리한 후 글자 단위에서 점차적으로 set을 만들어내는 Bottom Up 방식
- 훈련 데이터에 있는 단어들은 모든 글자 혹은 유니코드 단위로 set을 만들고, 가장 많이 등장하는 unigram을 하나의 unigram으로 통합하는 방식
- SentencePiece의 구현을 사용.
- 모든 숫자를 개별 숫자로 분할 (4123 -> 4, 1, 2, 3)
- 알 수 없는 UTF-8문자를 분해하기 위해 byte로 fallback.
- BPE(Byte Pair Encoding) 사용
Architecture
Transformer 기반으로 구현되어있으며 PaLM, GPT3, GPTNeo 방법론의 일부를 사용했다.
- Pre-normalization [GPT3]
- RMSNorm을 사용하여 훈련 안정성을 높이기 위해 하위 계층의 input을 정규화 하는 대신 ouptut을 정규화한다
- SwiGLU activation function [PaLM]
- ReLU activation function을 SwiGLU로 대체.
- Swish(x)=x⋅σ(x)
- GLU(x,v)=x⋅σ(v)
- SwiGLU(x,v)=Swish(x)⋅σ(v)
- We use dimension of (2/3)4d instead of 4d as a PaLM
- 주로 NLP에서 사용되며 Transformer모델의 효율성과 성능을 개선하는데 도움이 되는 activation function이다.
- ReLU activation function을 SwiGLU로 대체.
- Rotary Embedding [GPTNeo]
- absolute positinal embeddings 대신에 rotary positional embeddings(RoPE) 사용
Optimizer
- AdamW optimizer 사용 (\beta1 = 0.9, \beta2 = 0.95)
- cosine learning rate scheduler 사용
- weight decay 0.1 사용
- gradient clipping of 1.0 사용
- 2,000step warmup
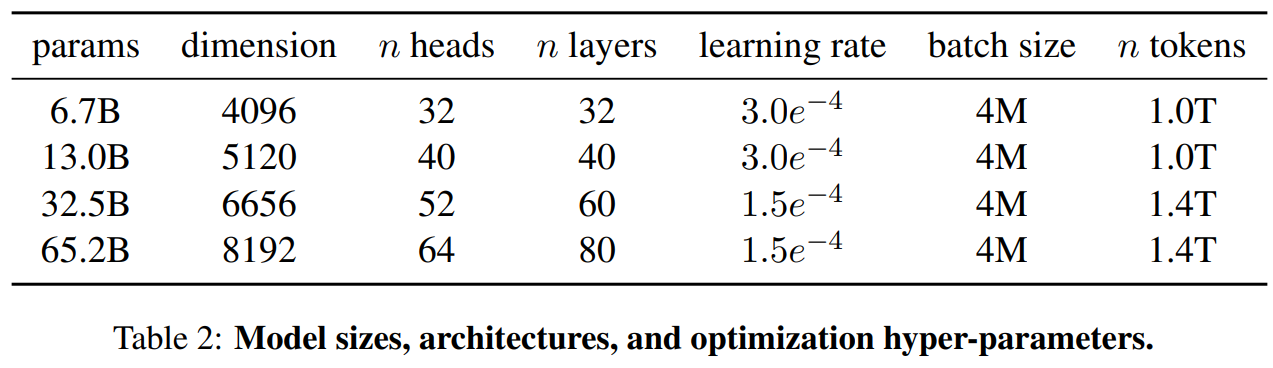
- 모델 크기에 따른 Batch-size 및 lr 변경 (Table 2 참고)
Efficient implementation
- Training Speed를 개선하기 위해 몇 가지 optimization 수행했다.
- 메모리 사용량과 런타임을 줄이기 위해 multi-head attention의 효율적인 구현을 사용했다.
- xformers 라이브러리에서 사용할 수 있는 해당 최적화는 <Self-attention does not need O(n^2) memory> 논문을 사용하였으며, Flashattention backward기법을 사용했다.
- 이는 모델 가중치를 저장하지 않고, Key/Query score를 계산하지 않음으로써 달성했다.
- 또한 training efficiency를 달성하기 위해, checkpoinging으로 backward pass를 수행하는 동안 activations 수를 줄였다.
- 더 정확하게는 Linear Layer의 output과 같이 compute 비용에 많이 드는 activation을 저장
- 이는 PyTorch의 autograd에 의존하지 않고, transformer layers에 대한 backward function을 수동으로 구현하여 달성하였다.
- 해당 최적화 이점을 충분히 누리기 위해 <Reducing activation recomputation in large transformer models>에서 설명한 대로 model 및 sequence 병렬처리를 사용하여 모델의 memory usage를 줄여야한다.
- 또한 activation 연산과 네트워크를 통한 GPU간 통신(all_reduce연산으로 인해)도 가능한 한 겹치지 않도록 한다.
- 650억개 매개변수 모델을 훈련할 때, 2048개의 A100 GPU(80GB of RAM)에서 초당 380개의 토큰/GPU를 처리했다.
- GPU만 약 563억원 어치다;
- 즉, 1.4T 개의 토큰에 대한 학습에 약 21일이 소요되었다
'LLM' 카테고리의 다른 글
| LLaMA-1를 알아보자 - 4편, Instruction Finetuning과 Bias및 Toxicity, Misinformation (1) | 2024.04.27 |
|---|---|
| LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 3편, Main Result (0) | 2024.04.24 |
| LLaMA: Open and Efficient Foundation Language Models를 알아보자 - 1편, Introduction (0) | 2024.04.22 |
| GPT3에 대해 이해해보자 (GPT 3편) - Language Models are Few-Shot Learners (0) | 2024.03.21 |
| GPT-2에 대해 이해해보자 (GPT 2편) (0) | 2024.03.20 |



