
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Inductive Bias
- Two Pointer
- 정규화
- BFS
- pytorch
- SQL
- mobilenet
- 백준
- Depthwise Separable Convolution
- 연산량 감소
- 1x1 Convolution
- CROSS JOIN
- get_dummies()
- 인접행렬
- 엔터티
- dp
- 데이터모델링
- resnet
- numpy
- SQLD
- SQLD 후기
- outer join
- bottleneck
- dfs
- 그래프
- feature map
- skip connection
- depthwise convolution
- 식별자
- 인접리스트
- Today
- Total
SJ_Koding
제3회 ETRI 휴먼이해 인공지능 논문경진대회 대상 리뷰 (ICTC2024 발표) 본문
+) 25.04.14: 제 4회 ETRI 휴먼이해 인공지능 논문경진대회가 개최됐네요! 이번에는 데이콘에서 대회 운영을 돕습니다.
해당 포스팅 내용이 좋은 참고가 되길 바랍니다.
해당 방법론이 유용하고 도움이 되었다고 판단되시면 아래의 인용정보를 기입해주시길 바랍니다.
@inproceedings{na2024pixleepflow,
title={PixleepFlow: A Pixel-Based Lifelog Framework for Predicting Sleep Quality and Stress Level},
author={Na, Younghoon and Oh, Seunghun and Ko, Seongji and Lee, Hyunkyung},
booktitle={2024 15th International Conference on Information and Communication Technology Convergence (ICTC)},
pages={810--815},
year={2024},
organization={IEEE}
}제 4회 ETRI 휴먼이해 인공지능 논문경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
제3회 ETRI 휴먼이해 인공지능 논문경진대회
본 대회는 한국전자통신연구원(ETRI)이 주최하고 과학기술정보통신부와 국가과학기술연구회(NST)가 후원합니다
aifactory.space
- 주최 : 한국전자통신연구원 (ETRI)
- 후원 : 과학정보기술통신부, 국가과학기술연구회 (NST)
- 운영 : 인공지능팩토리 (AIFactory)
개요
해당 대회는 다양한 스마트폰, 스마트워치 센서 데이터가 주어졌을 때, 이를 활용하여 총 7가지의 라벨을 예측하는 모델을 개발하고 The 15th International Conference on ICT Convergence(ICTC 2024)와 연계하여 논문 투고 및 엑셉까지 이루어져야합니다. 제 4회 대회에서도 유사한 방식으로 경진대회가 진행될 것으로 보입니다. 해당 포스팅이 대회 진행에 좋은 참고자료가 되었으면 좋겠습니다. (출판할 논문내용은 출판이 되거나 arXiv에 업로드 되면 링크로 추가첨부하겠습니다.) --> https://www.arxiv.org/abs/2502.17469
PixleepFlow: A Pixel-Based Lifelog Framework for Predicting Sleep Quality and Stress Level
The analysis of lifelogs can yield valuable insights into an individual's daily life, particularly with regard to their health and well-being. The accurate assessment of quality of life is necessitated by the use of diverse sensors and precise synchronizat
arxiv.org
| 논문 모집분야
🟧 라이프로그 데이터를 이용한 수면, 감정, 스트레스 인식 및 추론
- 논문주제 : 라이프로그 데이터셋을 이용하여 일상 경험에서의 다양한 지표를 인식 및 추론하
데이터
추론 대상 (labels)
하루 단위로 이루어진 multi binary classification label입니다.
Q1. 전반적인 수면의 질
Q2. 감정 상태
Q3. 스트레스 상태
S1. 수면 시간
S2. 수면의 효율
S3. 잠에 드는 데 걸리는 시간(입면 잠복기, Sleep onset latency, SL)
S4. 입면 후 각성 시간(WASO, Wake after sleep onset)
주어진 데이터
2023년도에 측정된 데이터 및 2021년도에 측정된 데이터가 주어집니다. 이 때, 2023년도와 2020년도에서 측정에 사용된 센서가 다르며, 피실험자도 상이합니다.
가장 중요한 점은 2023년 데이터를 train셋, 2020년도의 8명의 실험자 중 4명은 validation셋, 나머지 4명은 실제 평가에 사용되는 test셋으로 지정되었다는 점입니다.
validation셋이라고 해서 학습에 사용할 수 없는 건 아닙니다. 따라서 validation셋이 비교적 test셋과 분포가 비슷할 것으로 예상되며, 측정된 센서들이 정확히 겹치기 때문에 test셋을 추론하는데 가장 큰 힌트가 되는 데이터인 반면, train셋은 측정 센서가 달라 test셋과는 거리가 먼 데이터셋입니다.
train셋을 활용해보고자 train포함 학습, Domain Adaption등등 다양한 기법을 실험해보았지만 train셋을 사용하지 않았을 때가 성능이 훨씬 우수했습니다. 이는 test셋과 데이터 분포가 크게 상이하여 오히려 학습에 방해가되는 현상으로 추정했습니다.
데이터는 총 아래 그림과 같이 18개의 센서를 가집니다(validation, test). 각 센서는 주파수가 상이하고, 결측치 시간도 상이합니다. 즉 동기화 과정이 반드시 필요할 것입니다. (저희는 논문에 Channel이라는 용어를 사용했습니다. 이는 데이터에 포함된 센서의 개수를 의미합니다.)
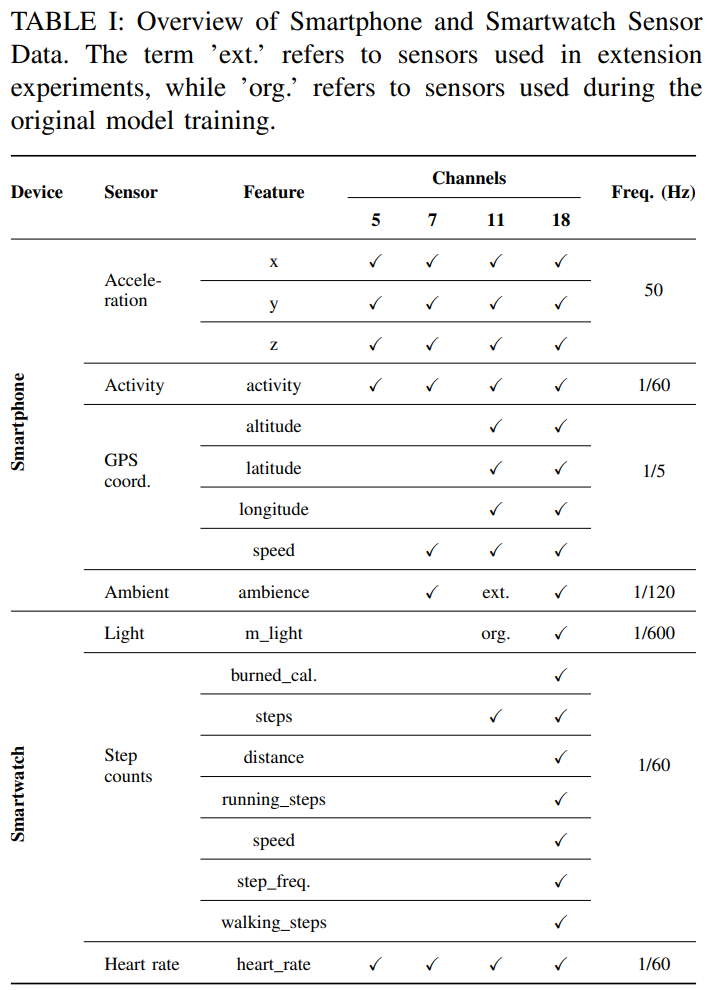
외부데이터 사용이 허용되었음에도, 외부데이터를 활용하지 못한점이 아쉬운 점으로 남지만 validation셋만으로도 충분한 성능을 이끌어 낼 수 있었습니다. (실제 검증에만 사용되는 validation셋과 혼동하면 안됩니다. 주어진 데이터셋이 validation으로 쓰라고 주어졌지만, train에 사용한 데이터입니다. 규칙에 위반되지 않습니다.)
HOW?
논문을 작성하면서 저희 방법론을 "PixleepFlow"라고 지칭했습니다. 대충 감이 오시나요?
물론 스트레스 지표도 추론을 하지만, 수면과 큰 관련이 있는 대회이다보니 Pixel + sleep의 합성어로 이름을 명명했습니다. 여기서 Pixel은 흔히 말하는 이미지 데이터의 한 칸의 정보를 나타내는 단위를 의미합니다. 즉, 저희는 이미지 변환을 적극 활용하여 성능향상을 도출했습니다.
pixleepflow의 프레임워크는 아래 그림과 같습니다.

Data preprocessing과정에서 3가지의 과정을 거쳐 만들어진 Composite Image와 Spectrogram이미지 데이터셋, 그리고 기존 Raw데이터셋을 만들어냅니다. 3가지의 과정은 아래와 같습니다.
1. Frequency Normalization
다양한 센서들은 서로 다른 주파수(Hz)를 가집니다. 동기화를 위해 주파수를 정규화하는 과정이 필요했는데, 이를 위해 1Hz단위로 데이터를 집계하여 매 초마다 가장 가까운 데이터 포인트를 매핑하는 방식을 채택했습니다.
2. Synchronization
데이터는 00:00:00부터 23:59:59까지 총 86,400(24시간)에 대한 값으로 하나의 데이터셋으로 동기화됩니다. 매 초의 데이터로 기록함으로써 동기화된 데이터는 다양한 형태로 변환이 가능합니다.
3. Interpolation
주파수가 1Hz이상인 경우에 결측치가 발생하며, 애초에 결측치인 경우도 존재합니다. 이를 위해 linear interpolation을 적용하였고 데이터의 시작이나 끝 부분에 데이터가 존재하지 않을 경우에는 데이터의 과도한 변형을 방지하기 위해 해당 부분은 보간하지 않았습니다.
해당 변환된 데이터는 하나의 이미지에 모든 동기화 및 정규화된 데이터로 표현됩니다. 하나의 이미지는, 하루 단위의 이미지입니다. medical field에서 수면의 질을 판단할 때 시각화 된 신호를 보고 파악하는 경우가 있는 것으로 알고있고, 사람이 할 수 있으면 딥러닝도 반드시 할 수 있다는 저희 가치관이 있었기 떄문에 시도할 수 있던 방법이었습니다.
Raw데이터의 1D-CNN(resnet 매커니즘 사용), Spectrogram(Concat&Resnext), Image(seresnext)중에 Image데이터가 가장 성능이 우수하였습니다. Image데이터의 생김새는 아래와 같습니다. (확장실험의 11channel 데이터 예시)
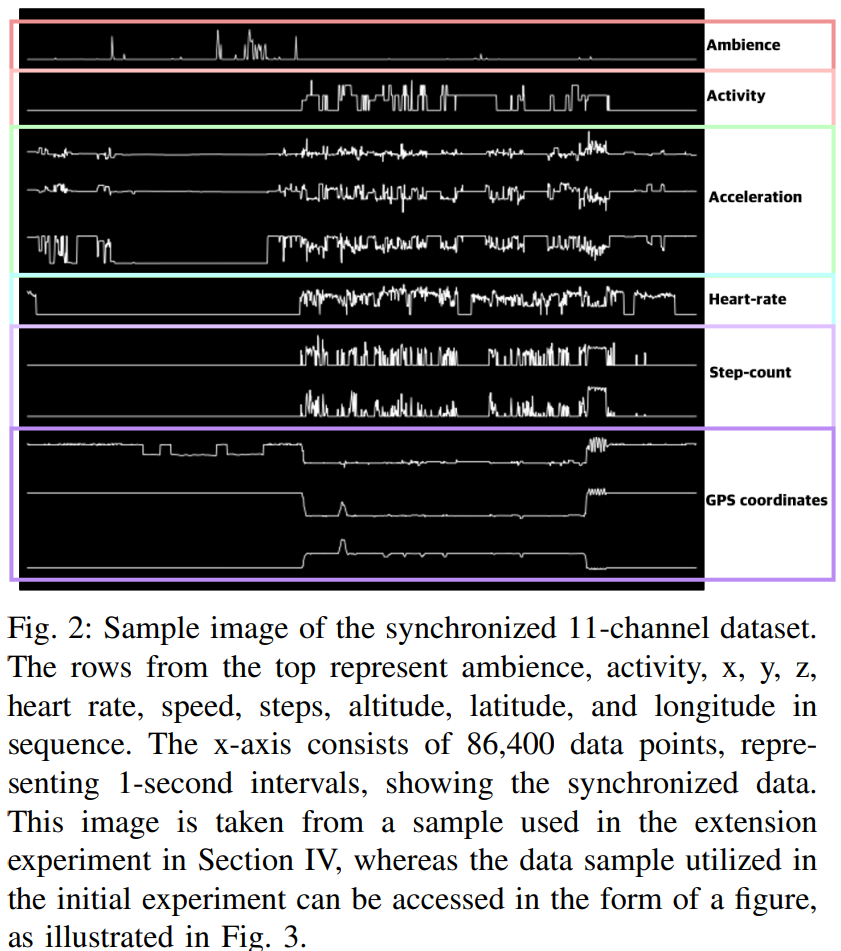
Experiments Result
모델은 주로 timm라이브러리를 사용하여 seresnext101_32x4d와 resnext101_32x32d를 사용하였으며, 적절한 앙상블을 통해 성능을 향상시켰습니다.
Test셋의 라벨은 알 수 없으므로, 자체적으로 K-fold validation score를 논문에 기입했는데, 일반적인 k-fold validation과 달리 각 fold별 최고 f1-score(macro)를 가진 모델들의 추론값을 평균내어 스코어를 기입했습니다.
실험 결과는 아래와 같습니다.

저희가 제안한 pixleep 방법론이 동일채널 가장 우수한 성능을 보였습니다.
Model Interpretation (XAI: eXplainable AI)
pixleep을 통해 만들어진 이미지 데이터에서 모델이 어느 센서정보를 주로 활용하고 보는지 시각화하기 위해 CAM기법을 통해 시각화 하였습니다. 여러 CAM종류 중에 성능이 비교적 우수했던 Full-CAM을 사용했습니다.
pixleepFlow방법론은 모델 설명 측면에 대해서도 두드러진 강점을 보입니다. SHAP지수를 이용한 방법과는 달리 어느 시간대에 어느 센서 값을 중요하게 볼 수 있었는지, 어떤 변화가 있을 때 중점을 두는지등을 한 눈에 시각화 할 수 있게 됩니다. 이는 확장하여 LLM과 적용한다면 자동화된 분석 결과를 의사에게 제공하여 참고자료로 활용할 수 있게 됩니다.

그리고 XAI의 결과물을 보았을 때 아래의 결론을 도출하였습니다.
activity: 모델 예측에서 중요한 지표로 작용하지 않음.
가속도: Y축과 Z축 센서가 중요한 특징으로 자주 사용됨.
심박수: 일관되게 중요한 요소로 식별됨.
침대에서의 시간(TIB): 수면 관련 패턴을 식별하는 데 주요 초점이 됨.
수면 중 스마트폰 사용:
모델은 스마트폰 확인과 관련된 미세한 움직임을 우선적으로 처리함.
이러한 움직임은 뚜렷한 움직임에 비해 덜 두드러졌음.
물론 데이터 수가 적기 때문에 일반적인 결과라고 보기 어렵습니다. 단, 주어진 데이터 내에서는 일반적으로 나타난 해석 결과입니다. 데이터셋이 더욱 풍부해질 때 고도화된 연구 결과가 많이 도출 될 것 같습니다.
총평
주어진 데이터셋의 양이 너무 적어 힘들었던 대회였습니다. train셋을 조금 더 잘 활용할 수 있었다면 큰 성능향상을 도출할 수 있었지만 그러지 못해 아쉽습니다.
대회를 하면서 시계열 데이터를 다루는 방법에 대해 심도있게 고찰할 수 있었고, 데이터 가공 및 분석능력도 향상되었습니다. 논문도 겸해 작성할 수 있어 좋았습니다.
공동저자: [NYH, OSH] <-- 고생해따!
+) ICTC에서 4(accept), 4(accept), 5(strong accept), 5(strong accept)로 개제 승인이 되었습니다. --> https://www.arxiv.org/abs/2502.17469
+) 해당 방법론은 참가자 중 최고 스코어를 기록하여 대상을 기록했습니다. 이로 인해 상금과 과학기술정보통신부 장관상을 수여받았습니다. 대단히 감사드립니다.


'Deep Learning' 카테고리의 다른 글
| ConvNeXt (A ConvNet for the 2020s, facebook) 논문 리뷰 (0) | 2024.04.04 |
|---|---|
| manifold와 Inverted Bottleneck의 설명 (1) | 2024.04.04 |
| Grouped convolution의 설명 및 PyTorch 예시 (1) | 2024.04.03 |
| Depthwise (Separable) Convolution의 설명 및 Pytorch 예시 (0) | 2024.04.03 |
| Bottleneck 구조(resnet)의 설명 및 Pytorch 예시 (0) | 2024.04.03 |



